One goal for iSpecies would be integrating taxonomic literature into the output. This has been motivated by Donat Agosti's efforts to make the taxonomic literature for ants available (see his letter to Nature about copyright and biopiracy doi:10.1038/439392a). For example, we can take a paper marked up in an XML schema such as the TaxonX Treatment Markup, extract the treatments of a name, and insert these into a triple store that iSpecies can query. For a crude example search iSpecies for the "Google ant" Proceratium google.
Now, marking up documents by hand (which is what Donat does) is tedious in the extreme. How can we automate this? In particular, I'd like to automate extracting taxonomic names, and references to other papers. The first can be facilitated by taxonomic name servers, particularly uBio's FindIT SOAP service. Extracting references seems more of a challenge, but tonight I stumbled across ParaCite, which looks like it might do the trick. There is Perl code available from CPAN (although when I tried this on Mac OS X 10.3.9 using cpan it failed to build) and from the downloads section of ParaCite. I grabbed Biblio-Citation-Parser-1.10, installed the dependencies via cpan, then built Biblio::Citation::Parser, and so far it looks promising. If references can be readily extracted from taxonomic markup, then this tool could be used to extract the bibliographic information and hence we could look up the references, both in taxon-specific databases such as AntBase, but also in Google Scholar.
Sunday, January 29, 2006
Wednesday, January 25, 2006
Google Maps Mania: North American Bird Watching Google Maps Mashup

Google Maps Mania: North American Bird Watching Google Maps Mashup notes the very slick combination of Google Maps and Flash to display ranges of North American birds at GeoBirds.com. The mashup uses data from the USGS Breeding Bird Survey and the Audobon Society's Christmas Bird Count.
Monday, January 23, 2006
Google, Yahoo, and the death of taxonomy?
I posted this on my iPhylo blog, but since it is more relevant to iSpecies, and indeed the talk is the reason I built iSpecies, maybe it belongs here (see, I'm so self-absorbed I've started to blog my blogs - sad).
Wednesday December 7th I gave a talk at the Systematics Association's AGM in London, with the slightly tongue in cheek titleGoogle, Yahoo, and the end of taxonomy? . It summarises some of the ideas that lead me to create iSpecies.org.
For fun I've made a Quicktime movie of the presentation. Sadly there is no sound. Be warned that if you are offended by even mild nudity, this talk is not for you.
The presentation style was inspired by Dick Hardt's wonderful presentation on Identity 2.0.
Wednesday December 7th I gave a talk at the Systematics Association's AGM in London, with the slightly tongue in cheek title
For fun I've made a Quicktime movie of the presentation. Sadly there is no sound. Be warned that if you are offended by even mild nudity, this talk is not for you.
The presentation style was inspired by Dick Hardt's wonderful presentation on Identity 2.0.
Friday, January 20, 2006
Identifiers for publications
Despite my enthusiasm for LSIDs, here are some thoughts on indentifiers for publications. Say you want to set up a bibliographic database. How do you generate stable identifiers for the contents?
There's an interesting -- if dated -- review by the National Library of Australia.
The Handle System generates Globally Unique Identifiers (GUIDs), such as hdl:2246/3615 (which can be resolved in Firefox if you have the HDL/DOI extension). Handles can also be resolved with URLs, e.g. http://digitallibrary.amnh.org/dspace/handle/2246/3615 and http://hdl.handle.net/2246/3615. DSpace uses handles.
DOIs deserve serious consideration, despite costs, especially if the goal is to make literature more widely available. With DOIs, metadata will go into CrossRef, and publishers will be able to use that to add URLs to their electronic publications. That means people reading papers online will have immediate access to the papers in your database. Apart from cost, copyright is an issue (is the material you are serving copytighted by sombody else?), and recent papers will already have DOIs. Having more than one is not ideal.
If Handles or DOIs aren't what you want to use, then some sort of persistent URL is an option. Their content can be dynamically generated even if they look like static URLs. For background see Using ForceType For Nicer Page URLs - Implementing ForceType sensibly and Making "clean" URLs with Apache and PHP. To do this in Apache you need a .htaccess file in the web folder, e.g.:
You need to ensure that .htaccess can override FileInfo, e.g. have this in httpd.conf:
This would mean that http://localhost/~rpage/iphylo/uri/234 would execute the file uri (which does not have a PHP extension). The file would look something like this:
Lastly, ARK is another option, which is essentially a URL but it copes with the potential loss of a server. It comes from the California Digital Library. I'm not sure how widely this has been adopted. My sense is it hasn't been, although the Northwest Digital Archives is looking at it.
If cost and hassle are a consideration, I'd go for clean URLs. If you wanted a proper bibliographic archive system I'd consider setting up a DSpace installation. One argument I found interesting in the Australian review is that Handles and DOIs resolve to a URL that may be very different to the identifier, and if people copy the URL in the location bar they won't have copied the GUID, which somewhat defeats the point. In other words, if they are going to store the identifiers, say in a database, they need to get the identifier, not the URL.
There's an interesting -- if dated -- review by the National Library of Australia.
The Handle System generates Globally Unique Identifiers (GUIDs), such as hdl:2246/3615 (which can be resolved in Firefox if you have the HDL/DOI extension). Handles can also be resolved with URLs, e.g. http://digitallibrary.amnh.org/dspace/handle/2246/3615 and http://hdl.handle.net/2246/3615. DSpace uses handles.
DOIs deserve serious consideration, despite costs, especially if the goal is to make literature more widely available. With DOIs, metadata will go into CrossRef, and publishers will be able to use that to add URLs to their electronic publications. That means people reading papers online will have immediate access to the papers in your database. Apart from cost, copyright is an issue (is the material you are serving copytighted by sombody else?), and recent papers will already have DOIs. Having more than one is not ideal.
If Handles or DOIs aren't what you want to use, then some sort of persistent URL is an option. Their content can be dynamically generated even if they look like static URLs. For background see Using ForceType For Nicer Page URLs - Implementing ForceType sensibly and Making "clean" URLs with Apache and PHP. To do this in Apache you need a .htaccess file in the web folder, e.g.:
# AcceptPathInfo On is for Apache 2.x, don't use for Apache 1.x
<Files uri>
# AcceptPathInfo On
ForceType application/x-httpd-php
</Files>
You need to ensure that .htaccess can override FileInfo, e.g. have this in httpd.conf:
<Directory "/Users/rpage/Sites/iphylo">
Options Indexes MultiViews
AllowOverride FileInfo
Order allow,deny
Allow from all
</Directory>
This would mean that http://localhost/~rpage/iphylo/uri/234 would execute the file uri (which does not have a PHP extension). The file would look something like this:
<?php
// Parse URL to extract URI
$uri = $_SERVER["SCRIPT_URL"];
$uri = str_replace ($_SERVER["SCRIPT_NAME"] . '/', '', $uri);
// Check for any prefixes, such as "rdf" or "rss" which will flag the
// format to return
// Check that it is indeed a URI
// Lookup in our database
// Display result
?>
Lastly, ARK is another option, which is essentially a URL but it copes with the potential loss of a server. It comes from the California Digital Library. I'm not sure how widely this has been adopted. My sense is it hasn't been, although the Northwest Digital Archives is looking at it.
If cost and hassle are a consideration, I'd go for clean URLs. If you wanted a proper bibliographic archive system I'd consider setting up a DSpace installation. One argument I found interesting in the Australian review is that Handles and DOIs resolve to a URL that may be very different to the identifier, and if people copy the URL in the location bar they won't have copied the GUID, which somewhat defeats the point. In other words, if they are going to store the identifiers, say in a database, they need to get the identifier, not the URL.

Using RSS feeds to notify clients when data changes
iChating with David Remsen earlier this morning, and he suggested using RSS feeds as a way of data providers "notifying" clients if their data has changed (e.g., if they've added some new names). Nice idea, and frees the client (such as a triple store) from having to download the entire data set every time, or to compute the difference between the data held locally and the data held by the remote source. Turns out that HTTP conditional GET can be used to tell if something has changed.
So, the idea is that a data source timestamps its data, and when data is modified it adds the modified records to its RSS feed. The data consumer peridically checks the RSS feed, and if it has changed it grabs the feed and stores the new data (which, in the case of a triple store can be easily parsed into a suitable form).
So, the idea is that a data source timestamps its data, and when data is modified it adds the modified records to its RSS feed. The data consumer peridically checks the RSS feed, and if it has changed it grabs the feed and stores the new data (which, in the case of a triple store can be easily parsed into a suitable form).
Tuesday, January 17, 2006

Monday, January 16, 2006
EXIF tags

Some images come with embedded metadata, such as EXIF tags or XMP. Images from AntWeb are a good example. These tags can be viewed by various programs, such as Adobe Photoshop, or utilities such as EXIF Viewer, seen here.
So, an obvious step would be (assuming we start using a triple store as a backend for iSpecies, and/or provide the results of a query in RDF) would be to extract metadata from EXIF tags. For example, the image http://www.antweb.org/images/casent0100367/casent0100367_p_1_low.jpg of Proceratium google in AntWeb has the following metadata:
File name: casent0100367_p_1_low.jpg
File size: 17811 bytes (0x0, infbpp, 0x)
EXIF Summary:
Camera-Specific Properties:
Camera Software: EXIFutils V2.5.7
Photographer: April Nobile
Image-Specific Properties:
Image Created: 2005:09:27 09:54:34
Comment: Attribution-NonCommercial-ShareAlike Creative Commons License
Other Properties:
Exif IFD Pointer: 196
Exif Version: 2.20
Hence, we could extract the relevant bits (author, date, copyright) and store those. This could be done in bulk using a tool such as ExifTool.
The example of AntWeb does show one weakness of free-text metadata. The image is licensed under "Attribution-NonCommercial-ShareAlike Creative Commons License".

For the photographer (such as AntWeb's April Nobile - seen here), it might be useful to create a FOAF file to link to, so that we have metadata about the creator of the images.
Monday, January 09, 2006
From the Blogsphere
Some interesting comments on iSpecies and related matters:
Hip Hop Offers Lessons on Life Science Data Integration
(Great title)
Ontogeny: iSpecies.org and Census of Marine Life Update
open data and open APIs enable scientific mashups
Loomware
Hip Hop Offers Lessons on Life Science Data Integration
(Great title)
Ontogeny: iSpecies.org and Census of Marine Life Update
I searched on Solenopsis invicta and thought the return information was great.
open data and open APIs enable scientific mashups
The biodiversity community is one group working to develop such services. To demonstrate the principle, Roderic Page of the University of Glasgow, UK, built what he describes as a "toy" — a mashup called Ispecies.org (http://darwin.zoology.gla.ac.uk/~rpage/ispecies). If you type in a species name it builds a web page for it showing sequence data from GenBank, literature from Google Scholar and photos from a Yahoo image search. If you could pool data from every museum or lab in the world, "you could do amazing things", says Page.
Loomware
This is too cool - some interesting examples of "Scientific mashups" from Richard Akerman. I followed the iSpecies link and was blown away by the data that was returned. I studied a damselfly called Argia vivida for my graduate degree and way back then finding data on the bug was not always easy. Searching the species in iSpecies bring up a TaxID number to the NCBI Taxonomy Browser, a list of papers from Google Scholar and images from Yahoo Images. This is an excellent example of what we have all been waiting for with the promise of the Web and web services in particular. The concept of a page for every species known is a dream come true for science, so this one is worth watching.
Friday, January 06, 2006
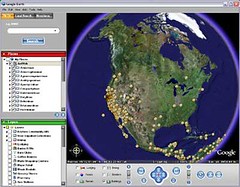
AntWeb-Google Earth Map
This is a nice example of the kind of thing that can be done when georeferenced specimen data are readily available. Need to think about doing this for iSpecies.
For more on AntWeb and Google Earth vist here .
{kind=link}
For more on AntWeb and Google Earth vist here .
Wednesday, January 04, 2006
Nature on mashups
Nature has an article by Declan Butler on "mashups", which mentions iSpecies, and also Donat Agosti's work on AntWeb and Antbase.
Subscribe to:
Posts (Atom)